I. Installation
II. Applied Exercises
Installing the reticulate package in RStudio
The following is a brief introduction on how to install the reticulate package in RStudio so that you can integrate Python libraries into the IDE (workspace) that shares code with R. This will enable you to eventually knit everything together with R and Python into one neat looking R Markdown document.
The importance of determining and setting the working directory cannot be stressed enough. Obtain the path to the working directory by running the getwd() function. Set the working directory by running the setwd("...") function, filling the parentheses inside with the correct path.
getwd()
setwd()To install specific packages, it is equally important to ensure to set the working directory to where base R is installed. In the console window, install the reticulate package by entering and running the following code using the install.packages() R syntax:
install.packages("reticulate")Using the reticulate package from R to install python libraries
The reticulate library allows us to install python packages in RStudio. However, to do that successfully, the syntax for calling the installation will change from install.packages() to py_install().
Load in the reticulate library and enter a new command for making a pandas (python) package installation through the library as follows:
library(reticulate)
py_install("pandas")Create an R Markdown file
Navigate to the “File” menu up top, click on “New File,” follow by “R Markdown.”
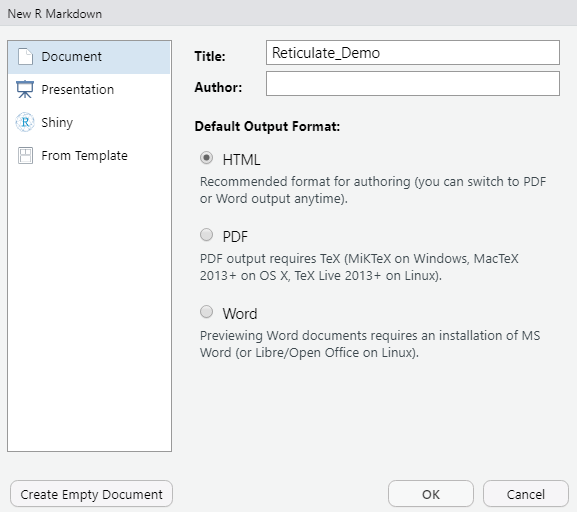
The following window will pop-up, prompting you to save the file according to various selections. Go ahead and name. In this case, an example title is set to “Reticulate_Demo.” The author field can either be filled in or left blank, and it is best to select the “HTML” radio button since knitting (compiling) the outputs between PDF and HTML can always be switched between at a later time. Go ahead and click “OK.”
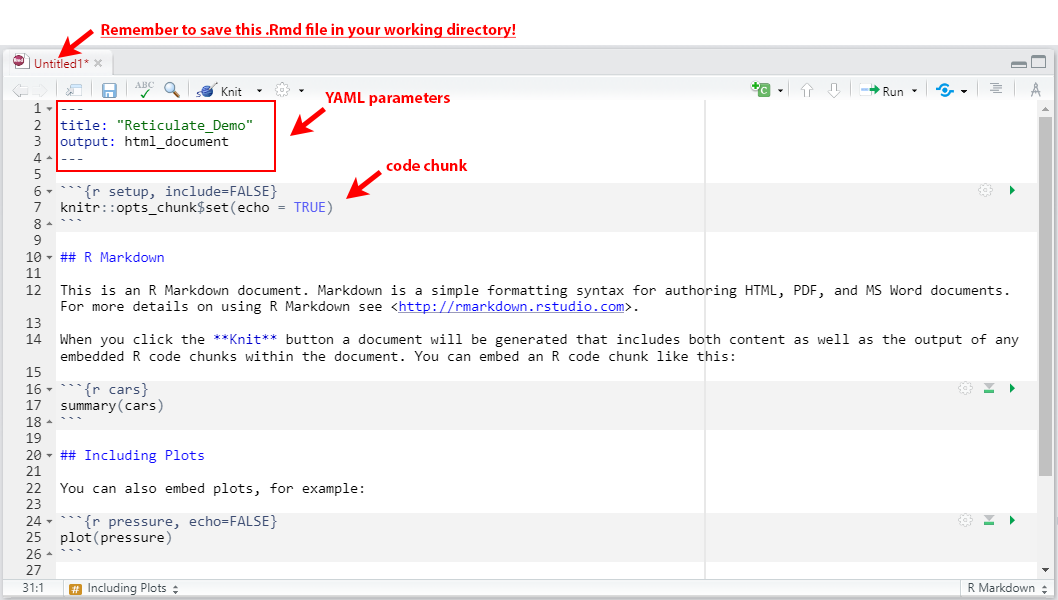
Take notice that the code window has now become pre-populated with several lines of helper code for formatting/ starting the R Markdown file with the correct syntax. In the following illustration below:
Lines 1-4 contain YAML parameters. YAML (short for “Yet Another Markup Language” or “YAML aint a Markup Language”) is a necessary component of the initiation of any R Markdown file, and should be placed in the file up top starting with three
---, and ending with the same---. The default values include “title” and “output.”Lines 6-8 contain what is called a code chunk. A code chunk is a specific section of the R Markdown document where code-specific syntax is placed and executed. A code chunk always begins with three ticks \(\text{```}\) followed by a
{}, and ends with three ticks \(\text{```}\) on a new line. To specify an R code chunk, placerinside the{}. Chunk options (or options for handling the chunk are always placed inside these curly braces). Some of these chunk options include:include = FALSEnegates the inclusion of code inside the chunk in the rendered output file, though it is still successfully executed and can be leveraged by succeeding chunks.fig,cap="..."allows for a caption to be associated with graphical outputs
Global options in one “master” code chunk preceding all other code chunks. These global options will apply to all code chunks inside the R Markdown file, and can be adjusted on an as-needed-basis. Below is a commented out example of such code chunk. Feel free to use this for your R Markdown files:
# ```{r global.options, include = FALSE}
# knitr::opts_chunk$set(
# cache = TRUE, # if TRUE knitr will cache the results to reuse in future knits
# fig.align = 'center', # how to align graphics in the final doc. 'left', 'right', 'center'
# fig.path = 'figs/', # file path to the directory where knitr shall store the graphics files
# results = 'asis', # knitr will pass through results without reformatting them
# echo = TRUE, # in FALSE knitr will not display code in the code chunk above it's results
# message = FALSE, # if FALSE knitr will not display any messages generated by code
# strip.white = TRUE, # if FALSE knitr will not remove white spaces at the beg or end of code chunk
# warning = FALSE) # if FALSE knitr will not display any warning messages in the final document
# ```
At this stage, we are ready to code in both R and Python using different code chunks.
Using R to Read-In and Examine a Dataset
- Initiate an R code chunk.
# ```{r}
#
#
# ```- Load the reticulate library
library(reticulate)- Read in an example dataset into R using the
read.csv("...", sep=";")function. This specific dataset is semicolon delimited, so the semicolon separator needs to be contained within the function. Assign the dataset to a dataframe called “white_wine.” In R, it is best practice to use the left arrow<-for assignment statements.
url="https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv"
white_wine <- read.csv(url, sep=";")- Inspect the first six rows of the dataset by using the
head()function. You should see a variety of properties (variables) associated with white wines. This is one “sanity” check for ensuring that the dataset was correctly read in.
head(white_wine)## fixed.acidity volatile.acidity citric.acid residual.sugar chlorides
## 1 7.0 0.27 0.36 20.7 0.045
## 2 6.3 0.30 0.34 1.6 0.049
## 3 8.1 0.28 0.40 6.9 0.050
## 4 7.2 0.23 0.32 8.5 0.058
## 5 7.2 0.23 0.32 8.5 0.058
## 6 8.1 0.28 0.40 6.9 0.050
## free.sulfur.dioxide total.sulfur.dioxide density pH sulphates alcohol
## 1 45 170 1.0010 3.00 0.45 8.8
## 2 14 132 0.9940 3.30 0.49 9.5
## 3 30 97 0.9951 3.26 0.44 10.1
## 4 47 186 0.9956 3.19 0.40 9.9
## 5 47 186 0.9956 3.19 0.40 9.9
## 6 30 97 0.9951 3.26 0.44 10.1
## quality
## 1 6
## 2 6
## 3 6
## 4 6
## 5 6
## 6 6Using Python to Read-In and Examine a Dataset
- Initiate a Python code chunk.
# ```{python}
#
#
# ```- Load the pandas library in Python. Read in the same dataset into Python using the
pd.read_csv("...", sep=";")function. Once again, assign the dataset to a dataframe called “white_wine.” In Python, the equals sign=is used for assignment statements.
import pandas as pd
white_wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/\
wine-quality/winequality-white.csv",sep=";")- Inspect the first five rows of the dataset by using the
df.head()function wheredfis yourwhite_winedataframe. You should see a variety of properties (variables) associated with white wines. This is one “sanity” check for ensuring that the dataset was correctly read in.
white_wine.head()## fixed acidity volatile acidity citric acid ... sulphates alcohol quality
## 0 7.0 0.27 0.36 ... 0.45 8.8 6
## 1 6.3 0.30 0.34 ... 0.49 9.5 6
## 2 8.1 0.28 0.40 ... 0.44 10.1 6
## 3 7.2 0.23 0.32 ... 0.40 9.9 6
## 4 7.2 0.23 0.32 ... 0.40 9.9 6
##
## [5 rows x 12 columns]