San Diego Street Conditions Classification
Abstract
The city of San Diego has become reliant upon a streets Overall Condition Index (OCI) that was designed and implemented by the United States Army Corps of Engineers. The company will provide recommendations to implement cost savings solutions.
Problem Statement
The city of San Diego has decided to “spend $700,000 to survey the condition of every street in the city so repairs and upgrades can be geared toward increasing social equity, fixing many long-neglected roads and boosting opportunities for bicycling” (Garrick, 2021). The challenge is to identify viable targets (streets) for future infrastructure projects for the city of San Diego. A high caliber consulting service that our company provides is instrumental for handling the following task. Classification of streets in above par conditions is a crucial step in establishing project feasibility. The city’s future depends on it.
Goals
- Predictive Analytics: Predict street viability presence/likelihood (good/fair vs. poor)
- Prescriptive Analytics: Identify cost effective solution to expand infrastructure projects
- Informative: Inform City of San Diego of the outcome in a timely manner (by 5/18/2022)
Non-Goals
While we will endeavor to provide recommendations and viable solutions that hinge on sound and proper data analytics, it is not in our capacity to “fix” issues including but not limited to traffic, parking meters, or real-estate assets or valuation.
Data Sources
Data will be stored on AWS service S3 Bucket that will communicate with AWS Sagemaker. The three files will be uploaded to S3 bucket.
Data Exploration
An S3 bucket is created in which a parent folder directory “raw_files” has three separate folders for each respective CSV file. The data is stored in an S3 Bucket that will communicate with AWS Sagemaker visa vie AWS Athena, a serverless “interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL” (Amazon Web Services, n.d.) to create the database and combine the three files into one single dataframe df.
Exploratory Data Analysis (EDA)
During the exploration phase, column names, data types, missing values, and size/shape of the dataset are initially documented in a new cell block. There are a total of 28 columns (features) and 23,005 rows that are a combination of floating point numbers, objects, and integers. Information on whether or not each respective column contains any null or missing values is represented herein. At this stage, missing values are uncovered in date_moratorium (4,426), date_start (1), date_end (7), street_name (16,874), and total_count (16,874), respectively.
Summary Statistics and Outlier Detection
Table 1 shows the summary statistics of the target variable, overall street condition.
Table 1
Overall Condition Index (OCI) Summary
| Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| 23005 | 74.79141 | 16.78405 | 0 | 66.3 | 79.06 | 87.3 | 100 |
Note. The mean is lower than the median, suggesting a negatively skewed distribution on the target variable.
Whereas the low (Q1 - 1.5*(IQR)) and high (Q3 + 1.5(IQR)) outliers are found to be 34.8 and 118.8, respectively, omitting these does not benefit long-term project goals. Resistance versus sensitivity to outliers in this endeavor is part and parcel of further analysis.
Data Ingestion
SQL by way of Athena (PyAthena) is used to ingest the data and Pandas is used to read in the SQL queries visa vie the “pd.read_sql()” function. More broadly, the Pandas library is used to read-in and explore the dataframe(s), while matplotlib and seaborn are used for visual explorations (graphical endeavors). An additional helper tool for table visualization (PrettyTable) is leveraged for supplementary visual appeal.
GitHub Repository Information
Moreover, histograms of all of the numeric features on the joined dataframe are produced to establish or detect the presence of degenerate distributions. One accompanying boxplot examining streets’ overall condition index (OCI) is presented visually, but illustrates the same behavior (summary statistics) that has already been depicted in Table 1. Figure 1 shows distributions of all of the numerical features from the entire dataset.
Figure 1
Histogram Distributions
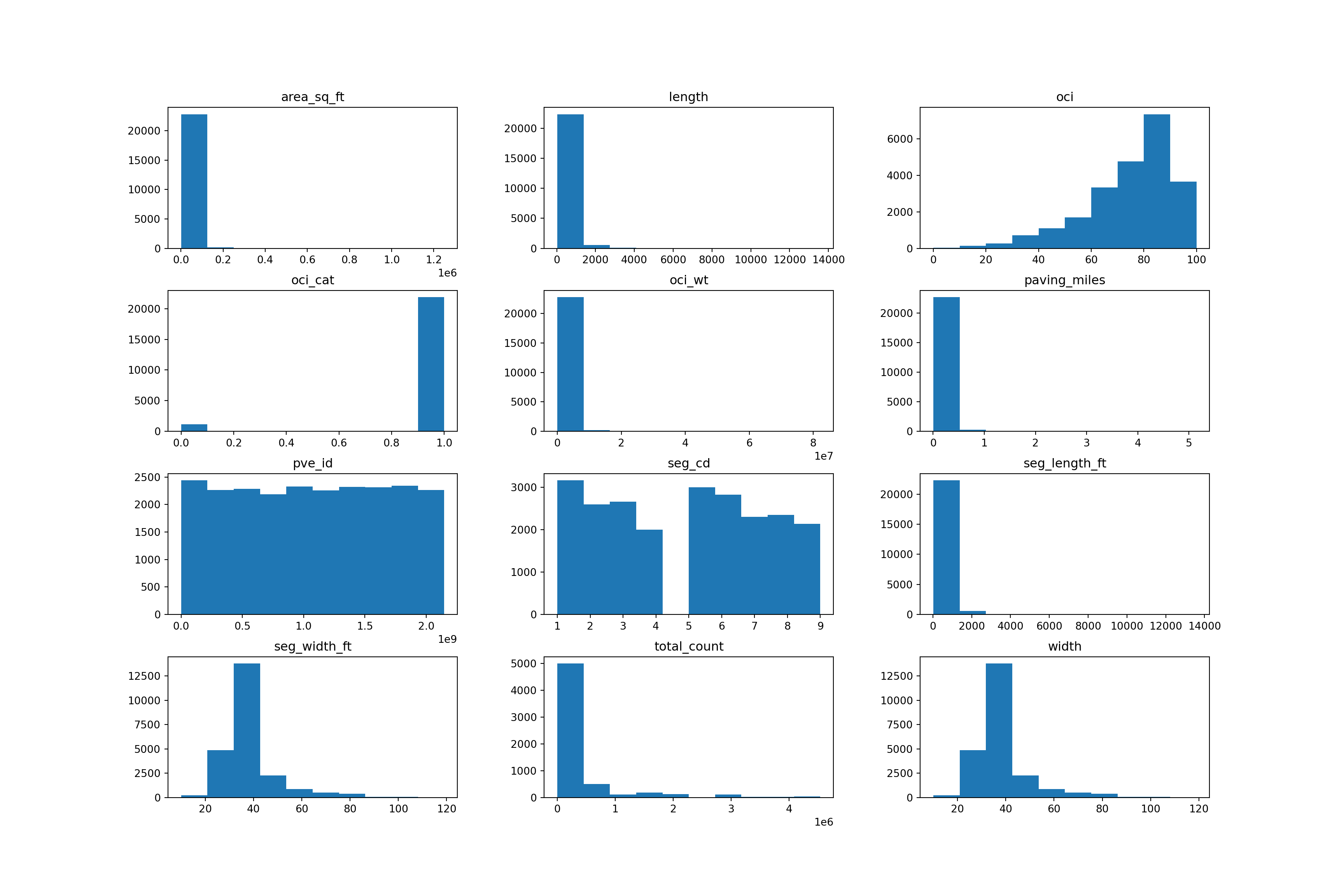
Note. Area in square feet, length, paving miles, and segment length in feet all exhibit right-skewed distributions. The OCI categorical feature is negatively skewed where there is a class imbalance between the 0 and 1 classes, respectively. This is supported by the ensuing Bias Exploration section.
Notwithstanding, all accompanying proportional measurements (i.e., height, width, length, etc.) are true and proper records acquired by the city of San Diego. No immediate transformation (normalization or standardization) is required in order to avoid the potential adverse effect of a high bias, low variance model whereby “a higher bias would not match the data set closely” (Wickramasinghe, 2021).
Pavement identification and total count are of no value and should thus be removed from the dataset.
Bias Exploration
Bias exploration helps determine the extent and/or effect of imbalance data by looking at the target feature of Overall Street Condition Index Description (oci_desc) which provides information on the street quality with “good”, “fair,” and “poor” conditions, respectively. This effect is measured both numerically and represented visually on a bar graph. There are a total of 23,005 streets of which 6,105 streets are in fair condition, 15,758 streets in good condition, and 1,142 streets in poor condition. Figure 2 shows this categorical distribution in the accompanying bar graph.
Figure 2
Bar Graph of San Diego Street Conditions
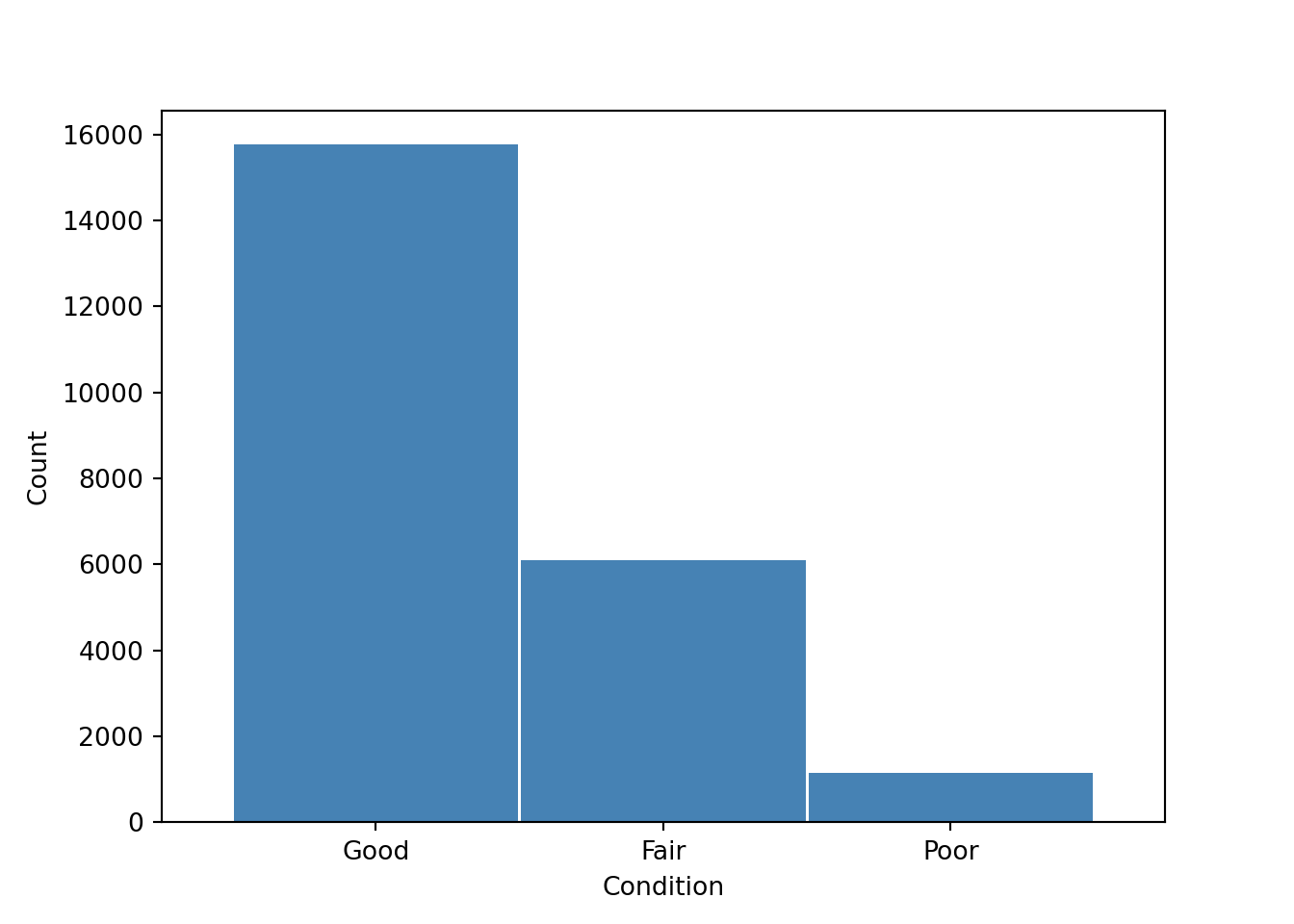
Whereas a method can be used to classify street conditions into multiple classes, it is easier to re-classify streets in “fair” and “good” condition into one category in comparison with the poor class. This, in turn, becomes a binary classification problem. Thus, there are now 21,863 streets in good condition and 1,142 in poor condition (only 5% of all streets). This presents a definitive example of class imbalance.
Class Imbalance
Multiple methods for balancing a dataset exist like “undersampling the majority classes” (Fregly & Barth, 2021, p. 178). To account for the large gap (95%) of mis-classed data on the “poor” condition class, “oversampling the minority class up to the majority class” (p. 179) is commenced. However, such endeavor cannot proceed in good faith without the unsupervised dimensionality reduction technique of Principal Component Analysis (PCA), which is carried out “to compact the dataset and eliminate irrelevant features” (Naseriparsa & Kashani, 2014, p. 33).
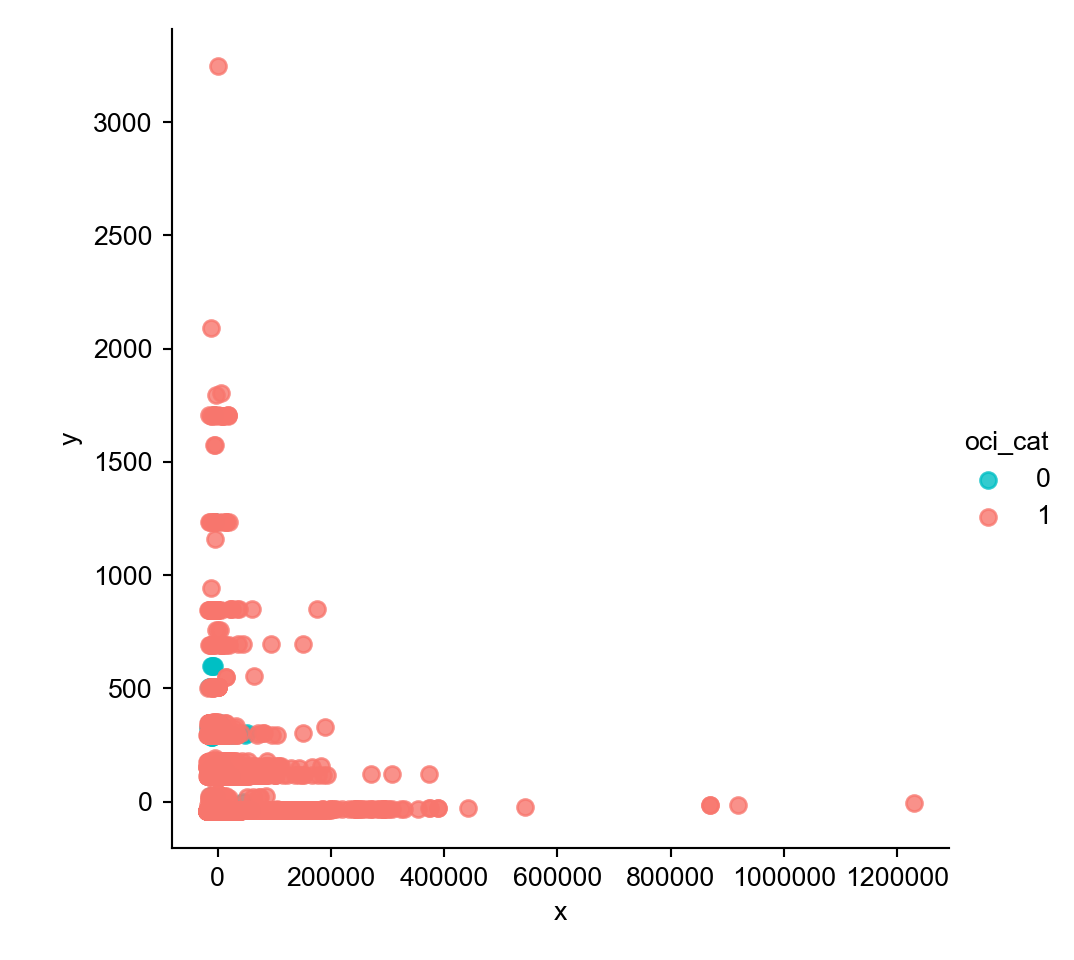
In this case, a new dataframe is reduced down into the first two principal components since the largest percent variance explained exists therein and because these principal components are depicted on the ensuing two-dimensional (x,y) scatter plot in Figure 3. A two-dimensional analysis is the most parsimonious one for illustrating additional visual confirmation of a class imbalance. The two classes are represented by light blue and pinkish red colors, of which the latter captures a larger number of. In other words, streets in good condition encapsulate a larger percentage of data than streets in poor condition.
Figure 3
Class Imbalance in Streets’ Overall Condition
 One final exploratory data analysis undertaking yields a triangular correlation matrix, an important step for examining the relationship between predictor variables and determining multicollinearity based on a threshold of a pearson correlation coefficient r = 0.75. Based on this criteria, area in square feet, oci weight, length, width, and paving miles are columns that are earmarked for subsequent removal, but this may not be necessary if too many features are to be removed. This is further discussed in the pre-processing section.
One final exploratory data analysis undertaking yields a triangular correlation matrix, an important step for examining the relationship between predictor variables and determining multicollinearity based on a threshold of a pearson correlation coefficient r = 0.75. Based on this criteria, area in square feet, oci weight, length, width, and paving miles are columns that are earmarked for subsequent removal, but this may not be necessary if too many features are to be removed. This is further discussed in the pre-processing section.
Measuring Impact
Specifically within the target variable, it is expected that the “good,” “fair,” and “poor” street condition classes being cast to dummy variables may slightly over-generalize street conditions by placing more emphasis on poorer conditions. To this end, these three variables are narrowed down to two whereby a binary classification follows suit (i.e., good condition vs. poor condition (0,1)).
Provided that certain machine learning methods and models have the ability to extract predicted probabilities, this will allow for a new column with such metrics to be feature engineered at the culmination of predictive modeling.
Security Checklist, Privacy and Other Risks
- No PHI, PII, user behavior, nor credit card data will be stored or processed since the information presented/provided herein is a matter of public record.
- This application will read/write to the following public s3 bucket: s3://waterteam1/raw_files/
- Bias by way of class imbalance is considered and addressed in order to assuage the potential effects of overfitting some or all of the machine learning methods/models that will be explored. Re-balancing the classes where an imbalance exists by oversampling or undersampling is one method of addressing this roadblock.
- One ethical concern that should be addressed is overfitting/underfitting the data commensurate with the initial notions of the viability/efficacy of the dataset at large.
Data Preparation and Data Scrubbing visa vie Pre-Processing
Date_start and date_end are subsequently removed after being concatenated into one uniform feature (date_days). Total count and street name represent the same information, and are unimportant features that are dropped from the dataframe altogether. Moreover, any duplicate columns are removed from the dataframe at large; this is an extra measure for avoiding post-join feature redundancy.
Predictive models only work with numerical values; therefore, categorical features such as func_class (function class), pvm_class (pavement class), and status are transformed into numerical values by mapping dictionaries of categorical values in ascending order. Creation of dummy variables is supported by the following information. For example, in the function class feature, the residential, collector, major, prime, local, and alley functional classes are converted to categorical values (1-6). Similarly, in the pavement class feature, AC Improved, PCC Jointed Concrete, AC Unimproved, and unsurfaced pavement classes are converted to values ranging from one to four.
Lastly, the current status of the job (i.e., post construction, design, bid/award, construction, and planning) is converted to categorical values between one and five. Features with no additional value are removed. Columns with explicit titles (i.e., names) and non-convertible/non-meaningful strings are dropped. Redundant columns (columns that have been cast to dummy variables) are dropped in conjunction with the index column which holds no value in this work.
For context and clarification columns with identifying information that are dropped include the project id, pavement event id, segment id, and project title. Additionally, the project manager’s email and phone number are removed to protect sensitive information in accordance with strict compliance standards; moreover, this information cannot be ingested into a viable machine learning algorithm.
Balancing the Dataset
The adaptive synthetic sampling approach (ADAYSN) is used because this is “where more synthetic data is generated for minority class examples that are harder to learn compared to those minority examples that are easier to learn” (He et al., 2008). This allows for the minority class to be more closely matched (re-sampled) to the majority class for an approximately even 50/50 weight distribution. This results in a larger dataset. Whereas previously there were 23,005 rows, there are now 43,572 (seven rows were previously dropped because of null values).
Train, Test, Validation Splits
To avoid overfitting, the main dataset is split into three respective component parts (dataframes), which will work to train, test, and validate the final model (Solawetz, 2020). Using sci-kit learn, the split is divided by 70%, 15%, and 15%, translating to 30,500 training rows, and 6,536 validation and test rows, respectively. Whereas specifying a stratify parameter allows the split function “to choose any data in the given dataset, causing the splits to become unbalanced” (Fregly & Barth, 2021, p. 181), a random state is set to 777 to ensure reproducible results.
Data Training and Modeling (Classical Approach)
The following experiment has two parts, first of which is conducted using a classical Logistic Regression model-based approach via scikit-learn. Logistic Regression is a viable algorithm for predicting target features that are categorical and with binary outcomes. To this end, the Logistic Regression function is imported directly from the sci-kit learn library, subsequently called, and fitted to the training portion with no hyperparameters other than the random state of 777 for reproducibility. Albeit, discussing performance at this juncture appears to be premature, it is important to note the following. With each iteration of restarting the kernel and running all cells, the accuracy score changes despite a solidified random state on the split data and model itself. Accuracy scores range in a broader-than-expected range of values in the 90th percentile. Modeling data in this way is similar to a “bring-your-own-script” scenario, but it has its limitations in reproducibility. Therefore, likening SageMaker to merely a Jupyter Notebook on the cloud minimizes its efficacy, power, and purpose.
Hyperparameters
To mitigate the classically trained Logistic Regression model, a randomized search is carried out in accordance with a k-fold cross validation of two repeats and five sample splits. A model search space is defined in terms of log uniform values between 1e-5 and 100 and set in conjunction with newton-cg, lbfgs, liblinear solvers, and l1, l2, and elasticnet penalty scoring mechanisms. The number of jobs is set to -1 in order to utilize all of the processing power, parallelizing the cpu usage over 100% of the cores. While accuracy is the predominant scoring criterion in this endeavor, it is only used to establish how often the predictive model is correct given the true positive and true negative scores, divided by the total. If it is higher than the original score, then this score is reproducible provided that the same random state and optimal hyperparameters displayed by the model are used. Precision, recall, and f1-scores are still considered by the final output since they are essential performance assessment scores necessary for a thorough, proper, and holistic model evaluation.
Data Training on Refined Algorithm Conducive to a Cloud-Centric Environment
Consequently, SageMaker’s built-in XGBoost algorithm is used because it is conducive to sound and proper cloud computing practices within the AWS ecosystem. Moreover, it is an “implementation of gradient boosted decision trees designed for speed and performance” (Brownlee, 2021). To begin the process, an Identity Access Management (IAM) role, region name, and XGboost container are defined. It is important to note that whereas the data has already been split into train, validation, and test sets, this is carried out in accordance with sklearn’s classic Logistic Regression model most suitable to an Anaconda-based coding environment. However, for this rendition of modeling and experimentation, the final dataframe df2 is once again split, but this time into train (70%) and test (30%) sets only, since model prediction and evaluation has been de-prioritized by the requirements (size and scope) of the project manager. The training data is subsequently transferred into the S3 bucket for storage and retrieval such that it can be called upon for repeated and/or supplemented endeavors.
Parameters
Furthermore, a SageMaker estimator is called upon and passed to an XGBoost variable. Inside the estimator function, the XGBoost container, role, instance count, type, and output path are parsed in.
Instance Size and Count
An instance count is the “number of Amazon EC2 instances to use for training” (Amazon SageMaker Python SDK, n.d.). In this experiment, an instance count of one is used. The instance type, on the other hand, is the “EC2 instance type to deploy this Model to” (SageMaker Python SDK, n.d.). In this case, the instance type is set to ml.m5.large, which is justified by a balanced two VPCUs, eight gigabyte memory, and a cost of only $0.115 per hour (AWS, n.d.). This is more than an adequate solution for a project of this scale and magnitude.
Model Evaluation
Whereas various performance metrics exist to assist in the holistic process of model evaluation, an accuracy score alone cannot provide a qualitative assessment of model performance, let alone predictive ability. Regardless, accuracy (~90%) is used in conjunction with precision (86%), recall (94%), and f1-score (90%), respectively to shed light on the baseline Logistic Regression performance (first modeling endeavor). These numbers are relatively high, which supports the idea or notion that the model can be used with a different dataset. That being said, since these metrics are not reproducible at a random state of 777, this endeavor does not lend itself to one of repeatability.
Therefore, performance assessment must be relegated to an accuracy score and confusion matrix from SageMaker’s built-in XGBoost model. Granted, these are minimal assessments at best, it is discovered that a classification rate of 100% does not provide the necessary framework to move forward with actionable recommendations on street condition classification for the city of San Diego. However, the model has room for improvement and can be re-trained and re-sampled.
Future Enhancements
Enhancement #1: Standardizing/Normalizing The Data
Standardization and normalization techniques are common strategies to improve the performance metrics of predictive models. These techniques are not required on each feature but are very useful when the features have different ranges (Jaitley, 2018). The difference between these two techniques is that normalization rescales the value range from 0 to 1, and standardization rescales the data with a mean equal to zero and a standard deviation of one (Geller, 2019). Additionally, standardization techniques assume a Gaussian distribution in the data, while normalization does not (Lakshmanan, 2019). Therefore, having used these strategies in certain numeric features (i.e., area in square feet and OCI description) could potentially improve the quality of the analysis. However, this remains to be seen in a forthcoming examination of this procedure.
Going back to the pre-processing, the histogram of the feature “area_sq_ft” shows a skewed distribution to the right, meaning that there are outliers present in the data. Eliminating these outliers could negatively impact the modeling since data would be lost. To mitigate the problem, standardization or normalization techniques could be applied to optimize the results of the final model without losing any data.
Enhancement #2: Different Algorithms and Tuning Mechanisms
Though it is clear that choosing a machine learning algorithm suitable for a classification task such as the one presented in this project is a great choice, elaborating on the significance of the choices prior to making them would have potentially benefited the outcome. For example, using XGBoost simply because it was readily available, accessible, and deliverable from a list of SageMaker’s built-in algorithms does not consider the need for modeling depth. To this end, understanding the classification problem at hand requires an expanded viewpoint, one that is rich with hyperparameter justifications and clarification on ensemble methods holistically.
It is hereby proposed that the Random Forest model be explored on a subsequent iteration of this project because this model because XGBoost places a larger emphasis on functional space, while the Random Forest classifier “tries to give more preferences to hyperparameters to optimize the model” (Gupta, 2021). When subtracting out the start date from the end date to achieve a total difference in days, it is discovered that there are 18,451 rows with no difference in project duration (zero days), which translates to approximately 80% of the data with immaterial values. Learning from this kind of sparsity would be better if the dataset remained unbalanced for the XGBoost model, but the Random Forest classifier may be a better choice because its hyperparameters are easier to tune and it can “easily adapt to distributed computing than Boosting algorithms” (Gupta, 2021).
Furthermore, an effort can be made to optimize the model with hyperparameters including but not limited to specifying the epochs, which are “the number of passes of the entire training dataset the machine learning algorithm has completed” (Bell, 2020). SageMaker HPT is more than capable of handling this workload since “it supports automatic HPT across multiple algorithms by adding a list of algorithms to the tuning job definition” (Fregly & Barth, 2021, p. 284).
Enhancement #3: Additional Features
Feature selection can impact bias and variance depending on the complexity of the model. Adding new features when the dataset is not big enough will work well on small datasets (El Deeb, 2015). The current dataset has enough observations to increase the number of features. Even if many features were eliminated from the tables, there is an opportunity to explore other datasets that can be merged into the current dataset to improve the overall quality of the final model and recommendations.
The final data set in this analysis consisted of ten features, but additional information such as car and pedestrian traffic can be added to the model. These features are not only helping the modeling part but are adding value to the recommendations that will be provided to the stakeholders. Prioritizing street enhancement by traffic might be in the best interest of the customer to allocate the resources that will impact the population of the city of San Diego. For example, the 24 hour total of all directions of vehicles combined (traffic count) can be reconsidered in the following formula:
\[\text{Traffic Volume = Total Count} \times \text{Area in Square Feet}\]
To determine the traffic volume, the total count is multiplied by the area in square feet. The 16,874 missing values should be imputed with a value of one such that upon multiplication of the two features, at least the total count would remain in the calculation of volume, whereas imputing with zero would render traffic volume in this new column unreported and immaterial.
References
Amazon Web Services. (n.d.). Amazon Athena. Amazon Web Services. (n.d.). Amazon SageMaker Pricing. Amazon Web Services. (n.d.). Data Lake Storage on AWS.Amazon Web Services. (n.d.). Data Warehouse Concepts. https://aws.amazon.com/data-warehouse/
Bell, D.J. (2020, May 27). Epoch (machine learning). Radiopaedia. Brownlee, J. (2016, August 17). A Gentle Introduction to XGBoost for Applied Machine Learning. Machine Learning Mastery. El Deeb (2015, May 28). 7 Ways to Improve your Predictive Models. Medium.Fregly, C. & Barth, A. (2021). Data Science on AWS. O’Reilly.
Garrick, D. (2021, September 12). San Diego to spend $700K assessing street conditions to spend repair money wisely. The San Diego Union-Tribune. Geller, S. (2019, April 4). Normalization vs Standardization – Quantitative analysis. Towards Data Science. Gupta, A. (2021, April 26). XGBoost versus Random Forest. Medium. He, H., Bai, Y., Garcia, E. & Li, S. (2008). ADASYN: Adaptive synthetic sampling approach for imbalanced learning.-
2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), 1322-1328.
https://ieeexplore.ieee.org/document/4633969
-
International Journal of Computer Applications, 77(3) 33-38. https://doi.org/10.5120/13376-0987