Litecoin Cryptocurrency Forecast – Variations on the Autoregressive Moving Average Model: A Time Series Analysis
Leonid Shpaner, Dingyi Duan
Abstract
Cryptocurrency and blockchain are often synonymous, but over the last ten years each unique yet non distinct entity has staked a claim into the world of financial technology—a territory riddled with numerical puzzles; blending the art of predicting future results and seasonality with the science of time series projections hinges on a few important notions. Past performance is not indicative of future results, though it is useful in establishing trajectories. Investors and speculators alike can leverage the power of predictive analytics to establish trends on an ever-changing, ever-evolving domain that will remain relevant into the distant future. This paper aims to provide more than a cursory analysis of the behaviors and patterns of Litecoin (LTC) over the last decade, leveraging seasonality of the autoregressive integrated moving average model to forecast a sound and proper price trajectory that will give prospective investors a healthy outlook for future growth.
Keywords: time series analysis, ARIMA, GARCH, Litecoin, cryptocurrency, forecast, volatility, R programming
Background: LTC Forecast - Variations on the Autoregressive Moving Average Model
2009 was an impactful year. An economic recession was underway, Barack Obama made history as the first African American President to be inaugurated into office, and Bitcoin (the world’s first cryptocurrency) launched a new era in financial technology known as blockchain. Since then, the market has witnessed a plethora of rapidly expanding offshoots of this technology, scaled to provide encrypted solutions to managing smart contracts and currency worldwide. Litecoin, one such cryptocurrency was launched as a peer-to-peer smart contract provider (digital currency) in 2011 by a computer scientist named Charlie Lee. To this day, while most people remain skeptical of the benefits of investing in cryptocurrencies at large, one cannot doubt its rapid expansion and integration into the financial markets. Litecoin started trading at roughly $3.00 (USD) per coin and is now listed as one of the top cryptocurrency providers on the market.
While cryptocurrencies are part of a relatively new landscape within the context of financial markets, it is difficult to neglect their efficacy in producing returns on investments, decentralized systems, and secure financial transactions. Every investment carries with it a degree (standard deviation) of risk, be it a stock, mutual fund, or call option. Assessing that risk or volatility need not be relegated to the confines of a client-fiduciary relationship with an investment firm. For example, making informed decisions from a mathematically oriented vantage point can make the difference between calculated arbitrage and gambling. Litecoin was established to be complementary to Bitcoin, where it “can be used for smaller amounts of money and have lower fees” (SFOX, 2015). For prospective investors that are looking to diversify their portfolios in an evolving market where the future knows no limits, forecasting its potential and entertaining the idea or notion that this can create a possible economic boom (in the long run) is at a minimum, a worthwhile endeavor.
Literature Review
Existing and Alternative Methods
Cryptocurrencies exhibit peaks and troughs in the span of their continuously fluctuating financial life cycles. Despite the approach in analyzing this data, the principles of inherent noise, non-stationarity, and volatility hold true to these time series. Whereas from a machine learning perspective principal component analysis helps reduce the number of dimensions in the training set of data, Gidea et al. (2020) impose PCA on clustered data; this is done to illustrate log transformed price projections from a graphical rendering standpoint alone. Omitting statistical assumptions from modeling is commensurate with removing the inherent bias-variance trade-off structure that abounds. This introduces the geometric method of “topological data analysis (TDA)” (Gidea et al., 2020, p. 1), which helps leverage the unsupervised, non-parametric learning methodology of the k-means clustering landscape. However, Gidea et al. (2020) concede the necessity of summarizing statistical output following the fitting of generalized autoregressive conditionally heteroskedastic (GARCH) models.
Moreover, it is noted that “statistical properties of such assets show…distinctly nonstationary behavior” (pp. 9-10). This warrants logarithmic transformation of the asset (i.e., Litecoin) in conjunction with differencing of the volatility shocks, which translate to 𝐿1-norms of the persistence landscapes as functions of TDA.
Forecasting Prices with R
Paul & Sadath (2021) make the case for using R versus Python in forecasting cryptocurrency time series for its relative novelty and reliability in producing statistical output. A short yet effective primer is given on blockchain technology—the instrumental force of smart contracts behind a network of distributed and decentralized ledgers used “to trade digital currency or tokens” (Paul & Sadath, 2021, p. 286). Bitcoin effectively instantiates the digital currency market, creating exponential price hikes through latter 2017, causing it to lose 70% of its value by early 2018 (p. 287). Suggestions for usage of deep learning models are made (i.e., bagging and stacking), citing ensemble methods as an “effective methodology to forecast cryptocurrency prices” (p. 287) and Twitter sentiment analysis. However, the predominant focus stays with time series analysis using the Prophet forecasting library in R, which can forecast “time series data based on additive model, in which non-linear trends are fit with yearly, weekly, and daily seasonality” (p. 288).
Moreover, recommendations for using autoregressive independent moving average (ARIMA), GARCH, and neural network autoregression (NNAR) models are made, citing better performance with NNAR with less volatility. However, “in case of extreme volatility ARIMA models show more accurate results” (p. 288). A cursory comparison of Bitcoin (BTC) prices with those of Ethereum (ETH) using Yahoo finance from 2015 until 2019 sets precedence for subsequent time series analyses for other cryptocurrencies to follow suit. Whereas establishing trends inherently necessitates a differencing of at least the first order, such a recommendation is not provided; albeit a log transformation of closing prices is noted wherein a one year out forecast is made.
Forecasting Comparison by Bayesian Time-Varying Volatility Models
Bohte and Rossini (2019) have contributed to a fine analysis of forecasting comparisons of cryptocurrencies using multiple Bayesian time-varying volatility models. Vector Autoregressive (VAR) models are generally used for empirical macroeconomic applications, and in this case, the Bayesian approach contains the stochastic volatility specification which is computationally tractable while possessing advantages in parameter uncertainty, computing of probabilistic statements and estimation with many parameters (Bohte & Rossini, 2019). To gain a better glance on if a more complex model can outperform a simple model on forecasting, a total of three models are used: The standard VAR model, VAR with stochastic volatility, and VAR with GARCH.
After using a series of point and density measurements which focus on 95% confidence intervals and Root Mean Squared Error (RMSE), the BVAR base model has shown a higher volatility in forecasting compared to the BVAR-GARCH model. The BVAR-SV and BVARXSV models have the highest percentages of all the cryptocurrencies, which suggests that using Stochastic Volatility will not give a good prediction overall using confidence intervals (Bohte & Rossini, 2019). Since the results between the BVAR model and the BVARX model are close to each other, there is not a clear distinction between these two and hence does not help establish a preference for a model of choice.
Half-Life Volatility Measure
Engle and Patton (2001) define half-life as the time required for the volatility to move halfway back towards its unconditional mean. To investigate the half-life volatility measure of some cryptocurrencies, John et al. (2019) propose choosing two GARCH family models (PGARCH (1, 1) and GARCH (1, 1)) with the Student’s-t distribution. After fitting the error term of the two GARCH models into various distributions (Gaussian, Student’s-t, and Generalized Error), the PGARCH model is selected (John et al., 2019). During the procedure, the following tests are performed with notable results:
The Jarque-Bera test for normality is statistically significant at the 5% alpha level for the return, meaning the return series is not normally distributed.
The Ljung-Box Q-statistics for the return and squared return show evidence of autocorrelation in both the return and squared return series since Q (30) and Q2 (30) are significant at the 5% level of significance.
The Quantile-Quantile plot is employed to confirm that the return is not normally distributed, which is confirmed by the presence of outliers at the tails since the points do not approximate the straight line.
GARCH(1,1) is proven to show non-stationarity while PGARCH(1,1) shows stationarity. Thus, the PGARCH model is chosen to investigate the half-life volatility measure of the return of Litecoin. The returns of the cryptocurrencies used in the paper exhibit volatility persistence and long memory by observation of the return series. A shock in the returns of Litecoin will take six days for it to mean revert without any further volatility (John et al., 2019). Therefore, information pertaining to the half-life measure and volatility persistence the cryptocurrency market is important for investors to consider.
Exploratory Data Analysis (EDA) and Initial Preprocessing Steps
Preprocessing has its own unique procedure within the context of time series analysis; this will be discussed at length in a later section. Nonetheless, the following data cleaning steps are discussed to establish a foundational analytics framework. The quantmod library in R is installed, loaded, and leveraged to extract the Litecoin (LTC-USD) symbol from Yahoo Finance, the source that is connected to this library. The data is presented as a time series object which is subsequently converted into a data frame and assigned to its own unique variable. The dataset contains 2,632 rows, representing the date range of September 17, 2014 through November 30, 2021, and 6 columns (variables), corresponding to open, high, low, close (adjusted prices), and volume.
Data prior to September 17, 2014 is not available for reasons not offered by the provider. OHLC is used to abbreviate open, high, low, close prices in United States Dollars (USD). There are 24 missing values, which are omitted by calling a function that uses complete cases. Incomplete price data should not be imputed (i.e., mean, median, or any other method), for a potential loss in data integrity may result. This lends the dataset to subsequent preprocessing with relative ease. Examination of the OHLC price histograms and boxplots, respectively, reveals non-normal distributions for all variables. Figure 1 uncovers these degenerate, long-tailed distributions.
Figure 1
Litecoin Historical Prices and Volume Distributions (September 17, 2014 – November 30, 2021)
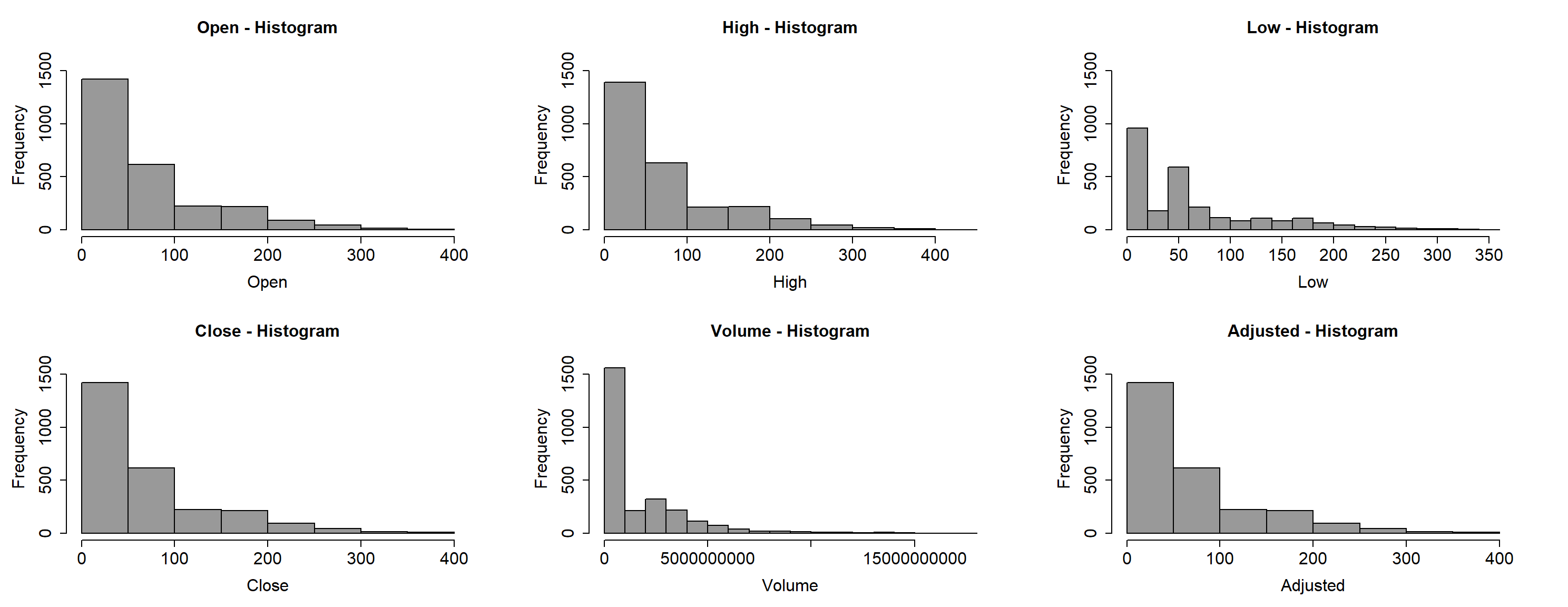
Note. Most prices are between $0 to $100 (USD), exhibiting rightly skewed distributions. The data is therefore pre-processed with a Box-Cox transformation with an estimated lambda \(\small \lambda\) of 0.2 for prices and 0.1 for volume. The skewness improves considerably where
\[\small \widetilde{\mu}_3=\frac{\sum_i^N(X_i-\bar{X})^3}{(N-1)\sigma^3}\]
and \(\small -0.383 \leq \widetilde{\mu}_3 \leq -0.055.\) However, this is strictly an exploratory preprocessing step to show potential improvement in estimating a Gaussian (normal) distribution, thus, not warranting integration into the original data frame; this is done to avoid loss of viability.
In evaluating Litecoin’s performance, the close price may be intrinsically of interest, but the “adjusted closing price is considered to be a more technically accurate reflection of the true value” (Bischoff, 2019). Summarizing the data frame yields the following five number summary. Whereas the minimum adjusted price for the last six years is $1.16, the first quartile is $3.88, with a median of $46.32, and a mean of $64.08; the third quartile is $87.12, and the maximum recorded price for this date range is $386.45. From the supplementary correlation matrix used to examine the relationships between all six variables, it is discernible that whereas the OHLC prices exhibit perfect multicollinearity at \(\small r=1,\) their relationship with volume is much less pronounced, where \(\small -0.56 \leq r \leq -0.58.\) The moderate correlation of \(\small r=0.57\) between the variable of interest (adjusted price) and volume does not lend itself for omission from ensuing analysis, nor does volume itself offer substantial influence on price. It exists to represent the full scope and context of the dataset at large. Granted, it will not be used within the context of this analytical endeavor. Moreover, principal component analysis (PCA) shows that 89.4% of the variance in the data is explained by the first principal component, where “the percentage of the total variance explained by each component” (Kuhn & Johnson, 2016, p. 38), translating to an effective dimension of 1. This is demonstrated numerically in Table 1 (in supplemental materials).
To graphically illustrate the historically adjusted prices, a new time series object in the form of a vector is created for the sole purpose of avoiding the representation of indexed time on the x-axis. Indexed time is harder to derive meaning from and defeats the purpose of graphical parsimoniousness. Therefore, it is important to see the impact of volatility visa vie market crashes and the corresponding years that this takes place. Furthermore, this object is placed into a plotting variable called litecoin_plot, with a starting date of 2014 and an annual frequency of 365; this is shown in Figure 2 below.
Figure 2
LTC Adjusted Closing Prices (2014 – 2021)
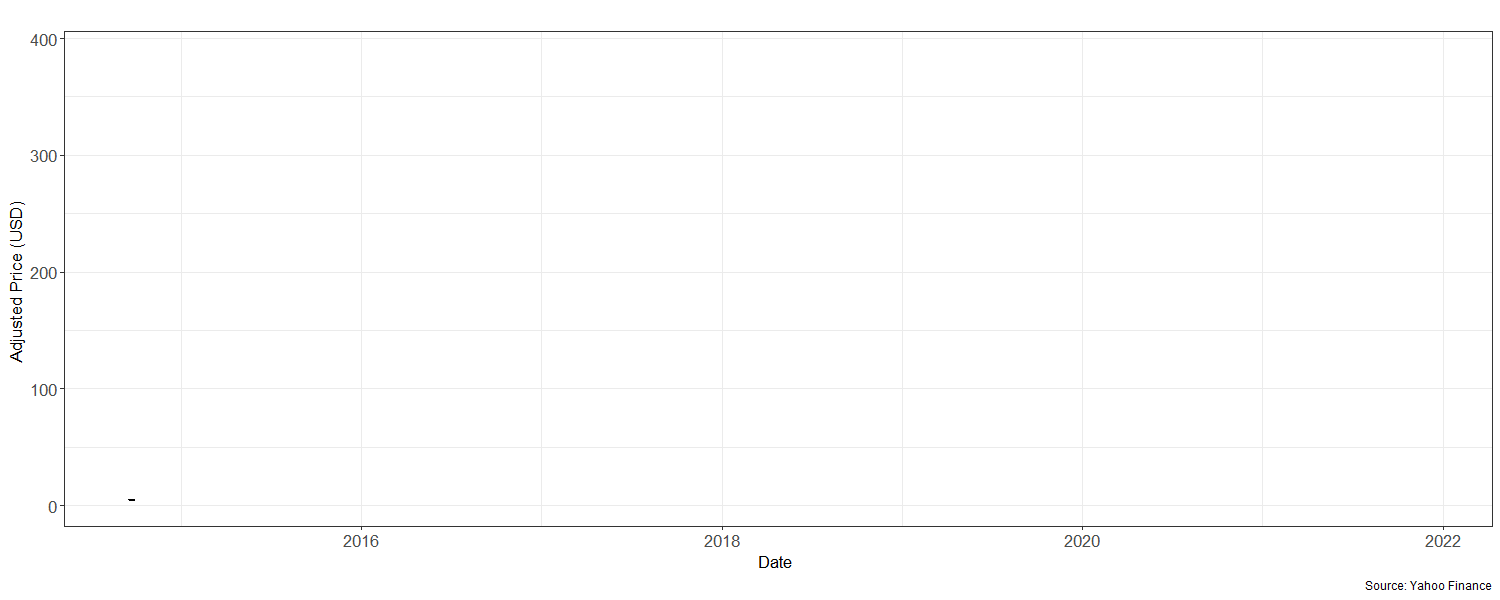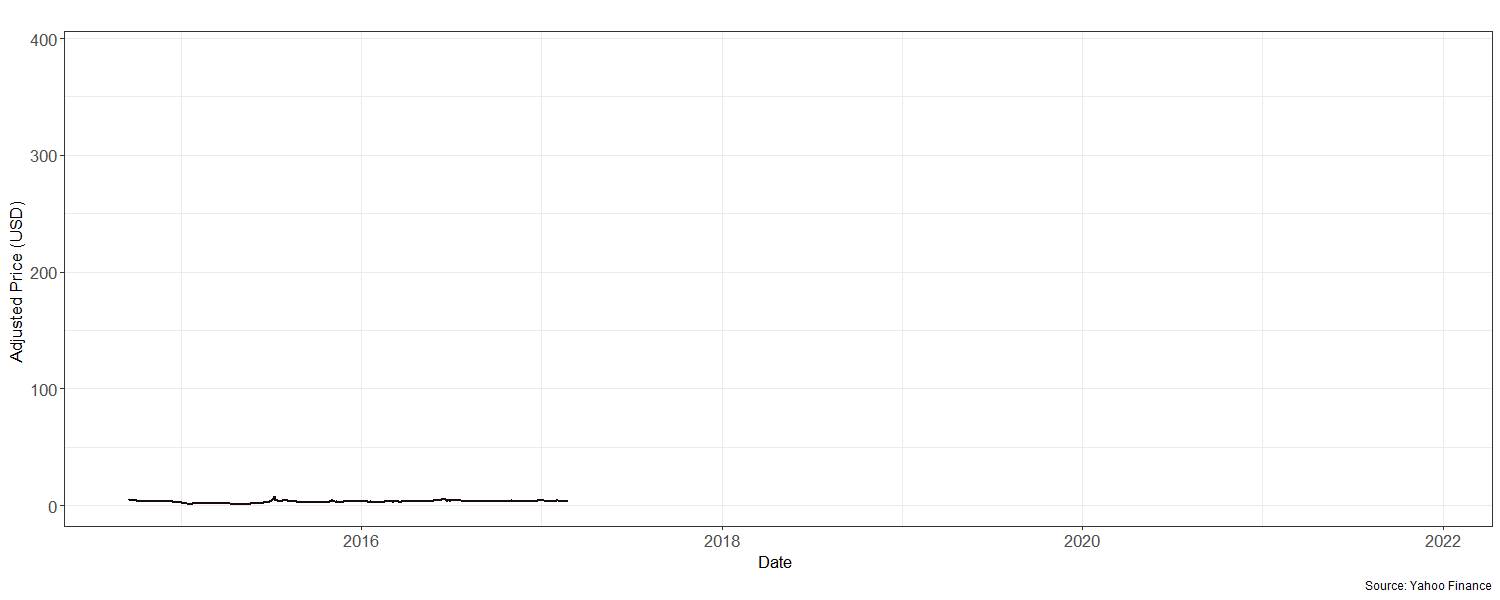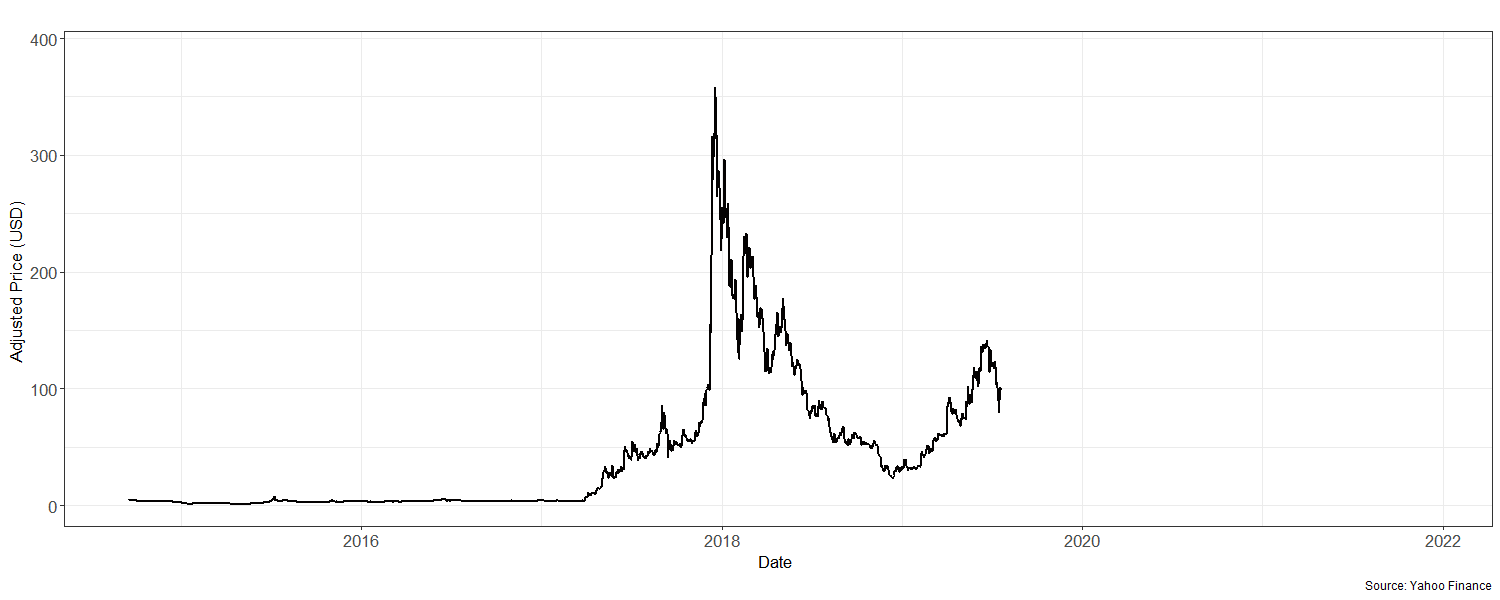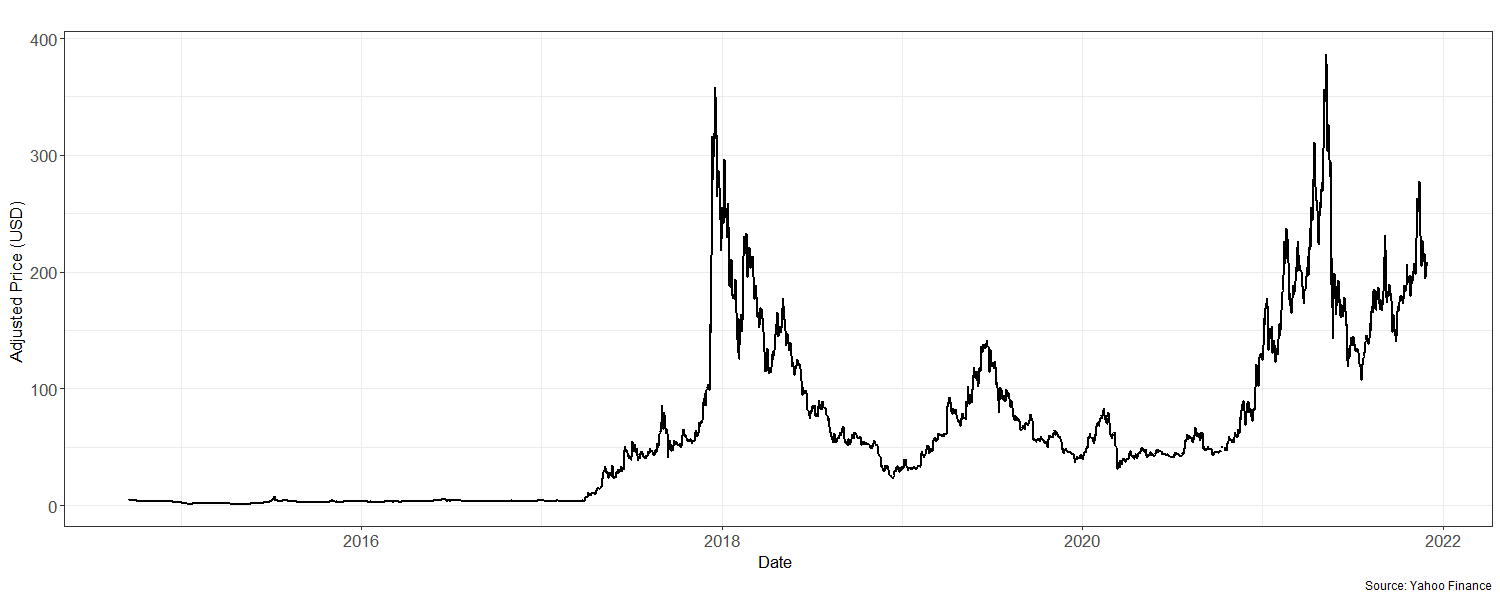 Note. Several crashes are observed (between 2017 – 2018 and 2020 – 2021).
Note. Several crashes are observed (between 2017 – 2018 and 2020 – 2021).
Spectral Analysis Cyclical Behavior Periodogram Filters
An ensuing spectral analysis to determine the degree of periodicity within the data frame is conducted because “the idea that a time series is composed of periodic components appearing in proportion to their underlying variances is fundamental to spectral analysis” (Shumway & Stoffer, 2019, p. 137). Two dominant peaks (0.001, 0.001) are recorded, translating to cyclical behavior between 675 and 1,350 days. However, the confidence intervals based on the chi-squared distribution for the first (149,449.40 to 21,775,218.90) and second (357,264.80 to 52,054,543.70) period frequencies are too wide to be of use. Additional periodogram analyses will be required (i.e., to measure the effects of tapering), but “the periodogram as an estimator is susceptible to large uncertainties. This happens because the periodogram uses only two pieces of information at each frequency no matter how many observations are available” (p. 153).
Methodology
Further examination of the Litecoin time series includes the autocorrelation function (ACF) and partial autocorrelation function (PACF). ACF “measures the linear predictability of the series at time t, say \(x_t\) using only the value of \(x_s\)” (Shumway & Stoffer, 2019, p. 20). The PACF does the same for a truncated lag length, explaining the partial correlation between the series its own lags. The sample ACF is defined as follows:
\[\small \rho \text{ }x(h) = \frac{\gamma(x(h)}{\gamma x(0)} = \frac{( X_{t+h}-\bar{X}) (X_t-\bar{X})}{\sum (X_t-\bar{X})^2} = \text{Corr}(X_{t+h,}X_t)\] An initial overview of the data shows that whereas the ACF gradually tapers off, the PACF cuts off after lag 1, thereby relegating the time series to the AR(1) model:
\[\begin{eqnarray} \small (x_t-\mu) = \phi(x_{t-1} - \mu) + \omega_t \small &=& \small (x_t - 64.0773) = 0.9960(x_{t-1} - 64.0773) + \omega_t\\ \small x_t &=& \small 0.256+0.996x_{t-1} + \omega_t \end{eqnarray}\]
Differencing and Stationarity
Establishing non-stationarity in a time series component requires the expression of the mean as a function of time t where \(\small E[y_t]=E[\beta_0+\beta_1t+\omega_t]=\beta_0+\beta_1t.\) Time is non-stationary because \(\small t_1 \neq t_2\) and \(\small \mu(t_1) \neq \mu(t_2).\) To mitagate the continuous fluctuations exacerbated by predominant peaks, troughs, and general volatility of cryptocurrency market, the year-over-year trends observed in Litecoin’s historically adjusted prices necessitate first order differencing \(\small \nabla y_t = y_t-y_{t-1}.\) Stationary is established visa vie the mean and autocovariance functions, respectively.
\[\begin{eqnarray} \small \nabla y_t = y_t-y_{t-1} = (\beta_1)(t-[t-1])+\omega_t-\omega_{t-1}. \text{ } \therefore \beta_1 + \omega_t - \omega_{t-1}. \end{eqnarray}\]
The mean function is applied in the following manner:
\[\begin{eqnarray} \small E[\nabla y_t] = E[\beta_1+\omega_t+\omega_{t-1}] = \beta_1 + E[\omega_t] - E[\omega_{t-1}] = \beta_1 \end{eqnarray}\] \(\small \beta_1\) is independent of time \(t\) and is thus stationary, which is also implicit using the autocovariance function:
\[\begin{eqnarray} \small \gamma \nabla x_t(t+h,h) &=& \small \gamma \nabla x_t (h) = \text{cov}(y_{t+h}, y_t)\\ \small &=& \small \text{cov}(\beta_1 + y_{t+h} - y_{t+h-1}, \beta_1 + y_t-y_{t-1})\\ \small &=& \small \text{cov}(y_{t+h}-y_{t+h-1}, y_t-y_{t-1})\\ \small &=& \small \text{cov}(y_{t+h},y_t) - \text{cov}(y_{t+h},y_{t-1}) - \text{cov}(y_{t+h-1,y_t})+\text{cov}(y_{t+h-1},y_{t-1})\\ \small &=& \small \gamma_y(h) - \gamma_y(h+1)-\gamma_y(h-1)+\gamma_y(h)\\ \small &=& \small 2\gamma_y(h)-\gamma_y(h+1)-\gamma_y(h-1) \end{eqnarray}\]
Differencing h shows that the autocovariance of the form \(\gamma\nabla y_t(h)\) is not dependent on time t. Figure 3 of the sample ACF shows a slow dampening which indicates a long memory process. The presence of non-stationarity can be established visa vie trend alone.
Figure 3
Sample Autocorrelation Function (ACF) Plot for Litecoin’s Adjusted Price
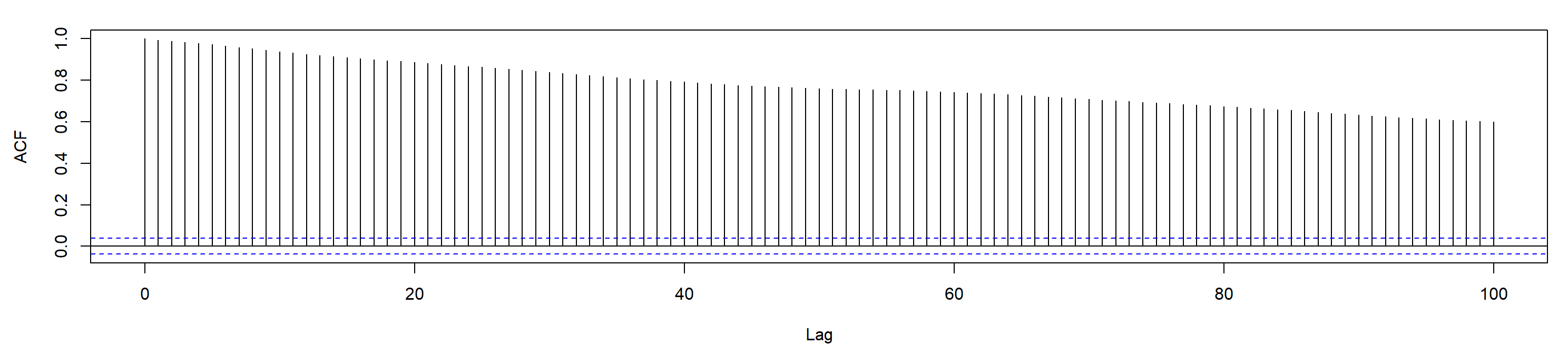
Note. A lag of 100 is enough to show these effects but is by no means the maximum lag for the series. Shumway & Stoffer (2019) present a basic equation for the expression of a long memory process as a byproduct of differencing fractional values where
\[\small (1-B)^dx_t = \omega_t,\]
asserting that “time series data tend to exhibit sample autocorrelations that are not necessarily large (as in the case of d=1), but persist for a long time” (p. 186). Figure 4 shows the effects of differencing the Litecoin time series; the remaining residuals are relegated to white noise, taking on a constant zero mean.
Figure 4
Litecoin Continuous Compound Return (2014 – 2021)
 Note. A continuous compound return is the direct result of differencing. The red line shows the mean annualized return of approximately 14%. This can be likened to the Dow-Jones Industrial Average, differenced data with a mean of zero and stationary property.
Note. A continuous compound return is the direct result of differencing. The red line shows the mean annualized return of approximately 14%. This can be likened to the Dow-Jones Industrial Average, differenced data with a mean of zero and stationary property.
While differencing can be effectively performed by a diff() function call on the log of the time series, an alternative method is prescribed whereby the differenced time series is a function of adjusted prices divided by the open prices minus one; the graphical output produced by this function is the same. Differencing the log of adjusted prices produces continuous compound returns over time. This adjusts the overall model to an order and magnitude of MA(1) whereby the ACF cuts off after lag 1. Establishment of a strategical analytics framework is key in forecasting the annualized returns of the Litecoin cryptocurrency. However, prior to commencing the analytics process it is important to establish the null and alternative hypotheses for the mean of returns r as follows:
\[\small H_0:\mu_r = 14\%; H_a:\mu_r>14\%.\]
ARIMA Models
Combining AR(1) with MA(1) produces an autoregressive integrated moving average model of ARIMA(1,0,1):
\[\small y_t = c + 0.341y_{t-1}-0.351 \varepsilon_{t-1}\]
where \(\small c=0.1457 \times (1-0.3409) = 0.096\) and \(\small \varepsilon_t\) is white noise with a standard deviation of 5.725. Subsequently, six ARIMA models are tested for performance visa vie AIC, initializing with ARIMA(0,1,0), a random walk with a zero mean:
\[\begin{eqnarray} \small \nabla y_t &=& \small y_t - y_{t-1}\\ \small y_t-y_{t-1} &=& \small \varepsilon_t, y_t = y_{t-1} + \varepsilon \end{eqnarray}\]
The Akaike Information Criterion (AIC) score is but one method deployed for model selection where the model with the lowest score is optimum. Table 2 (in the supplementary materials section) shows the corresponding AIC scores commensurate with each respective ARIMA model. From this vantage point alone, ARIMA(3,1,2) can be selected and represented in the following equation:
\[\small y_t = 0.663y_{t-1}-0.008y_{t-2}-0.040_{t-3}-1.664 \varepsilon_{t-1}+0.664 \varepsilon_{t-2}+ \varepsilon_t\] where \(c=0\) and \(\varepsilon_t\) is white noise with a standard deviation of 0.058.
At this juncture, operating from a strictly empirical standpoint and structure necessitates the use of an all-encompassing automatic ARIMA model that can determine its own set of unique and optimal parameters. Within the construct of the R environment, the auto.arima() function looks almost identical to that of the standard arima() function, with one exception; the “auto ARIMA takes into account the AIC and BIC values generated…to determine the best combination of parameters” (Singh, 2018). Moreover, “it should be noted that the AIC statistic is designed for preplanned comparisons between models (as opposed to comparisons of many models during automated searches)” (Kuhn & Johnson, 2016, p. 493) and is thus used to select an optimal model (ARIMA(3,1,3)).
GARCH Model
The GARCH model is a response to the volatility shocks of the market, which requires thousands of observations. The generalized form of the GARCH(1,1) model is expressed as follows:
\[\begin{eqnarray} \small \sigma^2_t &=& \small \alpha_0 + \alpha_1\alpha^2_{t-1}+\beta\sigma^2_{t-1}. \end{eqnarray}\]
The forecast for the GARCH(1,1) model originates at time t in: \[\begin{eqnarray} \small \sigma^2_t(1) &=& \small \alpha_0 + \alpha_1 \alpha^2_t + \beta_1\sigma^2_t \end{eqnarray}\]
and proceeds \(\small \ell\) steps ahead in the following manner:
\[\begin{eqnarray} \small \sigma^2_t(\ell) &=& \small \alpha_0 + (\alpha_1+\beta_1)\sigma^2_t(\ell-1), \ell=2, \cdots\\ \small \sigma^2 &=& \small \alpha_0/(1-\alpha_1-\beta_1)\\ \small [\sigma^2_t(\ell)-\sigma^2] &=& \small (\alpha_1+\beta_1)^{\ell-1}[\sigma^2_t(1)-\sigma^2]. \end{eqnarray}\]
Thus, as \(\small \ell \rightarrow \infty, \sigma^2_t(\ell) \rightarrow \sigma^2,\) where \(\small \alpha_1 + \beta_1 <1.\) When the volatility forecast approaches infinity, the long-term variance at time t approaches infinity in the same manner. This is conditional upon the presence of the persistence of volatility being less than 1. Thus, “the speed of mean reverting to the long-term variance can also be measured by the half-life \(\small \ell= \text{log}(0.5)/\text{log}(\alpha_1+\beta_1)\)” (Tsay, 2013, p. 245). The half-life is the amount of time that it takes for half of the volatility to diminish and revert to the mean—in essence, how long Litecoin’s volatility will endure in a post-shock condition prior to reverting to its natural state. Whereas there are 252 trading days in the stock market, cryptocurrencies operate continuously. Therefore, volatility is annualized for h-period returns and is defined by \(\small \sigma_{t,h,a} = \sqrt{365/h} \text{ }\sigma_{t,h},\) where a refers to annualized volatility and h refers to number of days. Figure 5 represents these volatility shocks which are calculated by the standard deviation of the return over annualized time.
Figure 5
Litecoin - Annualized Volatility
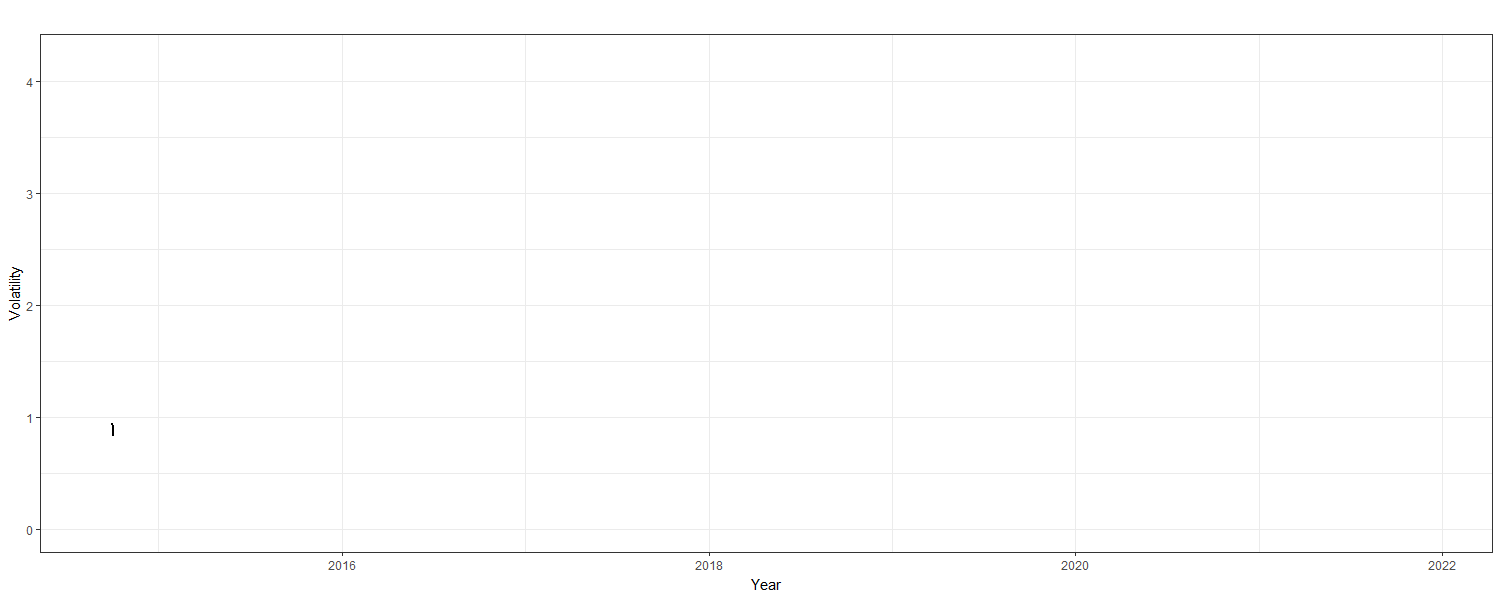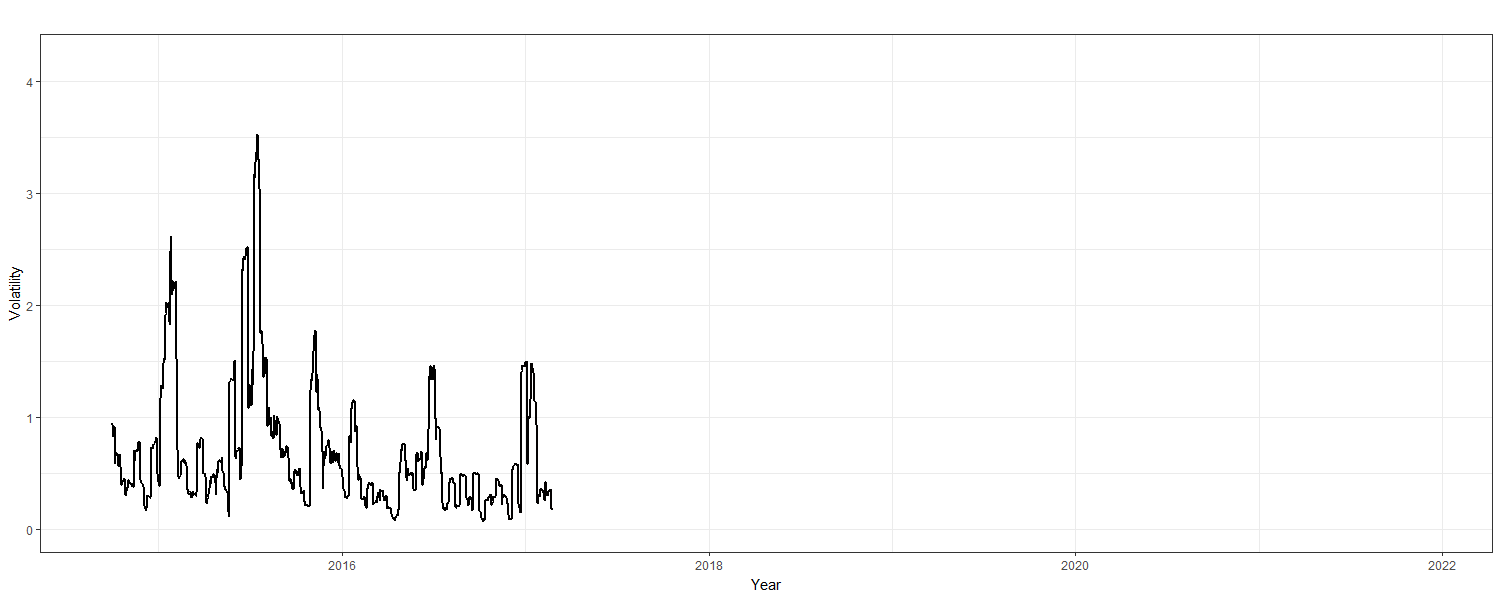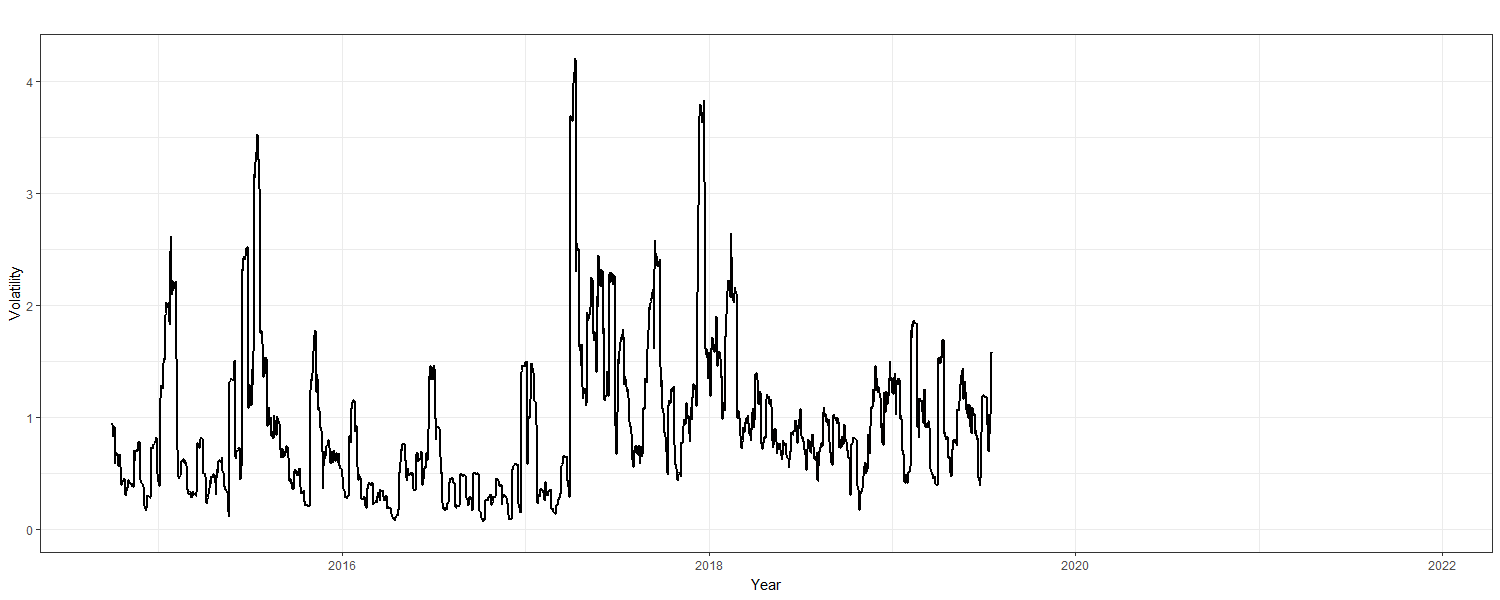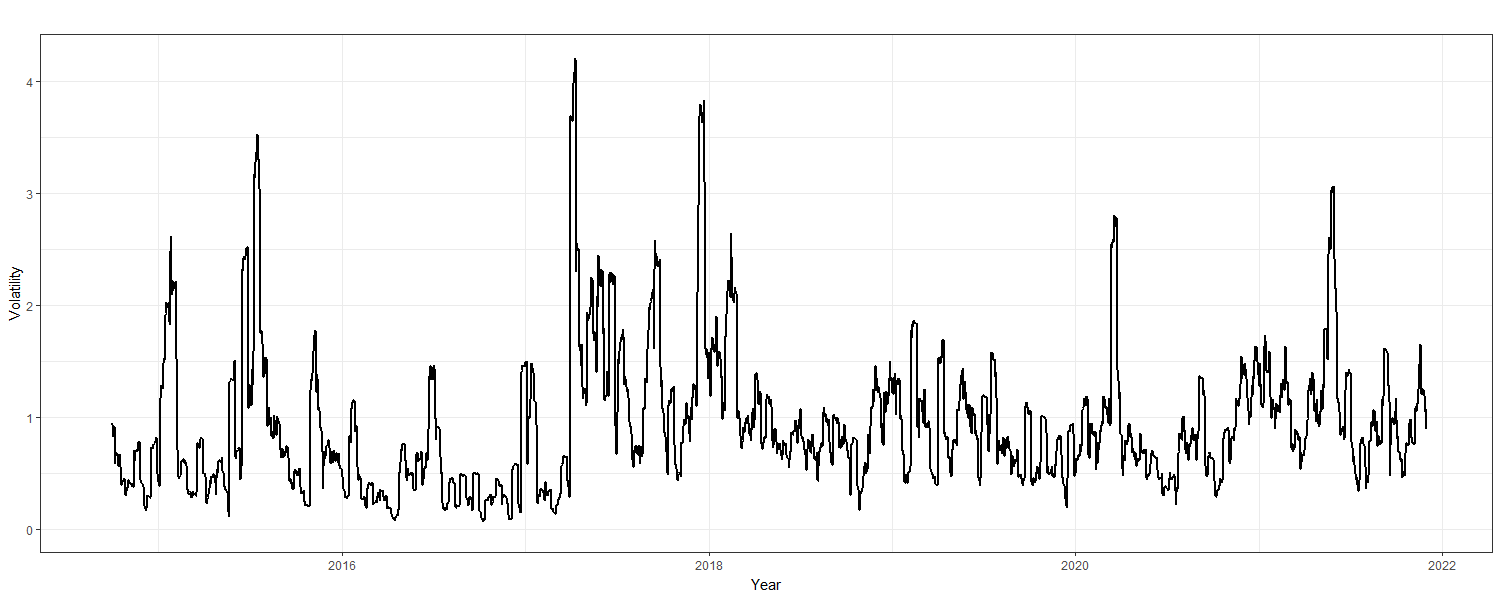 Volatility shocks are observed throughout the series; year 2017 notably shows one of the highest peaks. Analysis of these shocks is conducted with the rugarch package (v1.4-4; Ghalanos, 2020). GARCH is introduced as a response to these stochastic volatility shocks where GARCH(1,1) is the best model fit according to the conditional variable dynamics of the ensuing summary output. However, it is important to note that the mean estimate of 0.000735 with a standard error of 0.000524 bears no statistical significance at a p-value of 0.160717 where \(\small \alpha\)=0.05. The AIC and BIC are relatively low, expressing values of -3.506 and -3.488, respectively. More importantly, the weighted Ljung-Box test on standardized residuals shows corresponding lags with statistically significant p-values. Furthermore, the Adjusted Pearson Goodness-of-Fit “calculates the chi-squared goodness of fit test, which compares the empirical distribution of the standardized residuals with the theoretical ones from the chosen density” (Ghalanos, 2020). Herein, “the null hypothesis is that the conditional error term follows a normal distribution” (Tsafack, 2021). Each respective value presented is statistically significant, thereby rejecting a normal distribution (the null hypothesis) and corroborating the originally presented skewed Student’s t-distribution. Moreover, additional evidence for GARCH-like behavior is provided since the ACF and PACF in Figure 6 below are both tapering off incrementally.
Volatility shocks are observed throughout the series; year 2017 notably shows one of the highest peaks. Analysis of these shocks is conducted with the rugarch package (v1.4-4; Ghalanos, 2020). GARCH is introduced as a response to these stochastic volatility shocks where GARCH(1,1) is the best model fit according to the conditional variable dynamics of the ensuing summary output. However, it is important to note that the mean estimate of 0.000735 with a standard error of 0.000524 bears no statistical significance at a p-value of 0.160717 where \(\small \alpha\)=0.05. The AIC and BIC are relatively low, expressing values of -3.506 and -3.488, respectively. More importantly, the weighted Ljung-Box test on standardized residuals shows corresponding lags with statistically significant p-values. Furthermore, the Adjusted Pearson Goodness-of-Fit “calculates the chi-squared goodness of fit test, which compares the empirical distribution of the standardized residuals with the theoretical ones from the chosen density” (Ghalanos, 2020). Herein, “the null hypothesis is that the conditional error term follows a normal distribution” (Tsafack, 2021). Each respective value presented is statistically significant, thereby rejecting a normal distribution (the null hypothesis) and corroborating the originally presented skewed Student’s t-distribution. Moreover, additional evidence for GARCH-like behavior is provided since the ACF and PACF in Figure 6 below are both tapering off incrementally.
Figure 6
Litecoin Annualized Volatility - ACF and PACF
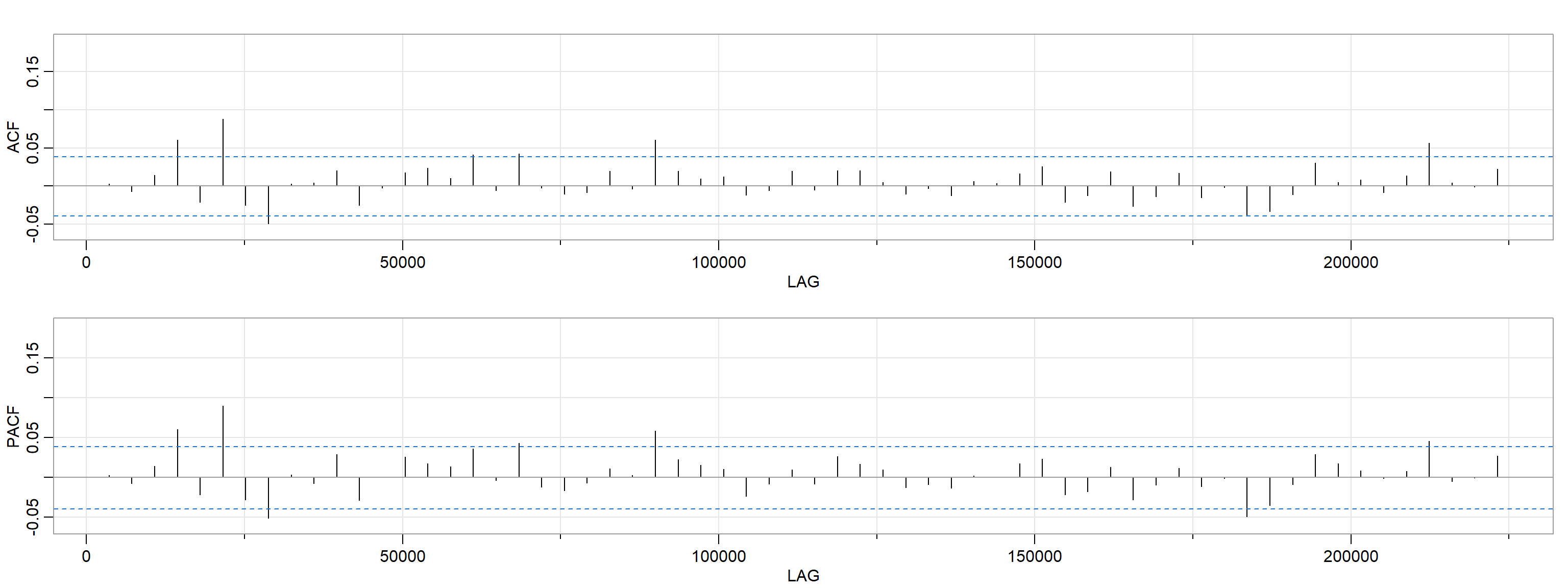 Note. The ACF and PACF is shown at a maximum lag of 500 to highlight the gradual tailing off effect. However, the code corresponding to these plots in the Appendix is not set to a maximum lag, as it “defaults to \(\sqrt{n}\) + 10 unless \(n\) < 60” (Stoffer & Poison, 2021).
Note. The ACF and PACF is shown at a maximum lag of 500 to highlight the gradual tailing off effect. However, the code corresponding to these plots in the Appendix is not set to a maximum lag, as it “defaults to \(\sqrt{n}\) + 10 unless \(n\) < 60” (Stoffer & Poison, 2021).
Summarized Results
Fitting the GARCH(1,1) model to Litecoin’s return data uncovers some interesting findings. For example, whereas the presence of stochastic volatility has been established through the lens of annualized returns, its persistence is highlighted visa vie Figure 7 where the conditional standard deviation is plotted versus returns. Two prominent shocks are observed in early 2018 and 2020.
Figure 7
Conditional Standard Deviation (vs |Returns|)

Note. The volatility trajectory is annualized through the end of 2021, expressing a standard deviation on return of approximately 0.058.
Revisiting the ARIMA(3,1,3) model is an important step before exploring predictive modeling. In so doing, additional findings are presented that are consistent with selection of an optimal model. The AIC score (-7446) is among the lowest of all the ARIMA models presented shown thus far. Table 2 shows that ARIMA(3,1,2) is slightly higher (-7453) by 7 units (supplementary materials). Moreover, the summary output table shows that all components of the moving average model are statistically significant where \(\small 0 \leq p \leq 0.002\). ARIMA(3,1,3) is represented in the following equation:
\[\small y_t = -0.181y_{t-1}+0.567y_{t-2} - 0.002y_{t-3} -0.186 \varepsilon_{t-1} -0.722 \varepsilon_{t-2}+ 0.540 \varepsilon_{t-3} + \varepsilon_t\] where c=0 and \(\small \varepsilon_t\) is white noise with a standard deviation of 0.058.
Figure 8 shows the ensuing graphical output for this model which contains the diagnostics for the standardized residual, ACF, Q-Q and Ljung-Box statistic.
Figure 8
ARIMA(3,1,3) Diagnostics
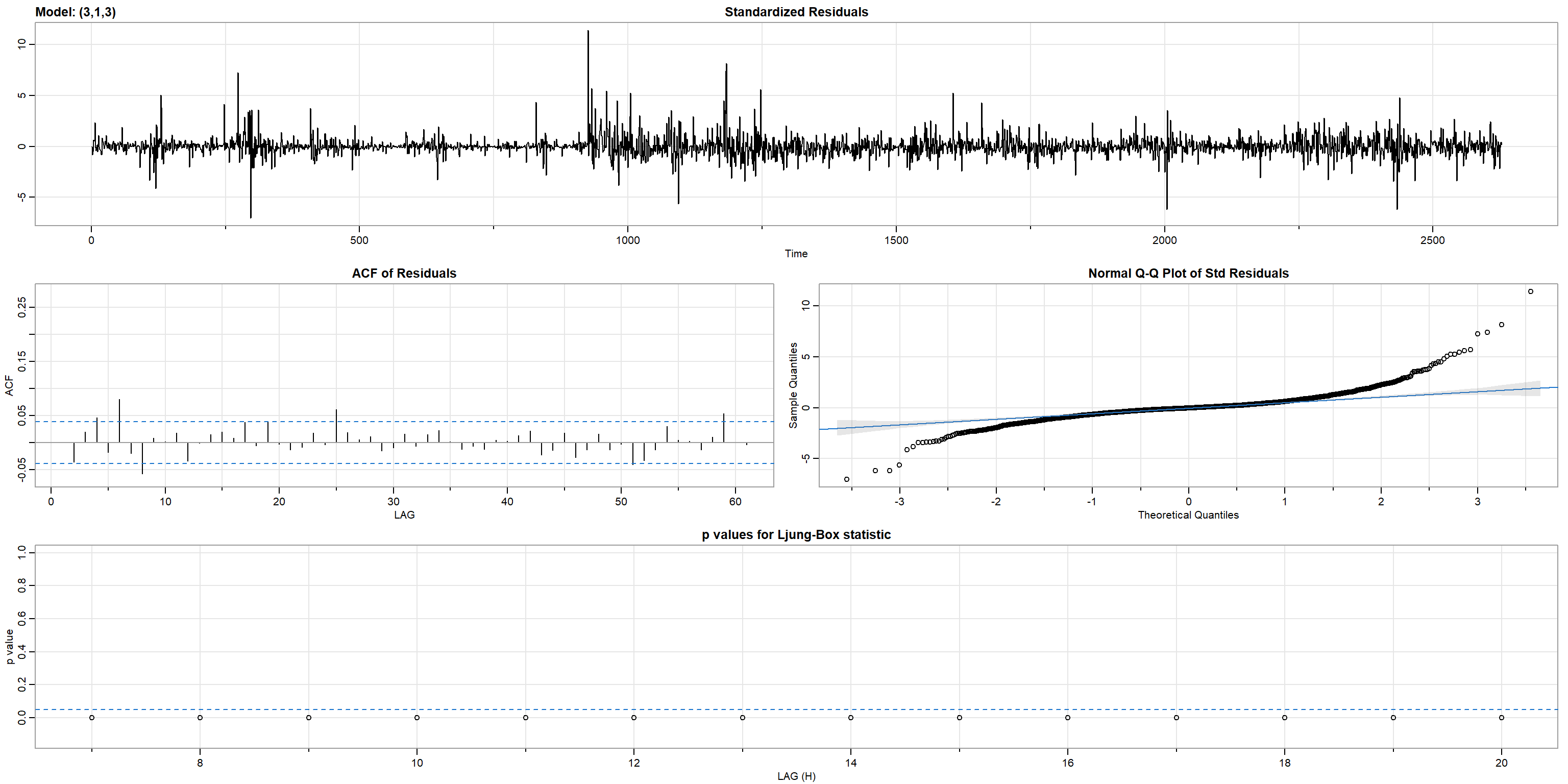
Note. The standardized residuals report trend-less and white noise-like behavior. The ACF of the residuals exhibits a sharp decline after lag 1, corroborating its MA(1) behavior. Moreover, the Normal Q-Q plot of the standardized residuals operates off the assumption of normality, albeit with a reasonable number of outliers at both tails. Lastly, the p-values shown in the Ljung-Box statistic plot are below the threshold of 0. Overall, the model has a good fit.
The modeling phase is complete, and an ensuing forecast of 41 days from November 30, 2021 is produced with a 95% confidence interval as shown in Figure 9 below. The time horizon (x-axis) is indexed on a numerical scale ranging from 2200-2500, where the trajectory is illustrated using a red color.
Figure 9
Forecasts from ARIMA(3,1,3) Model
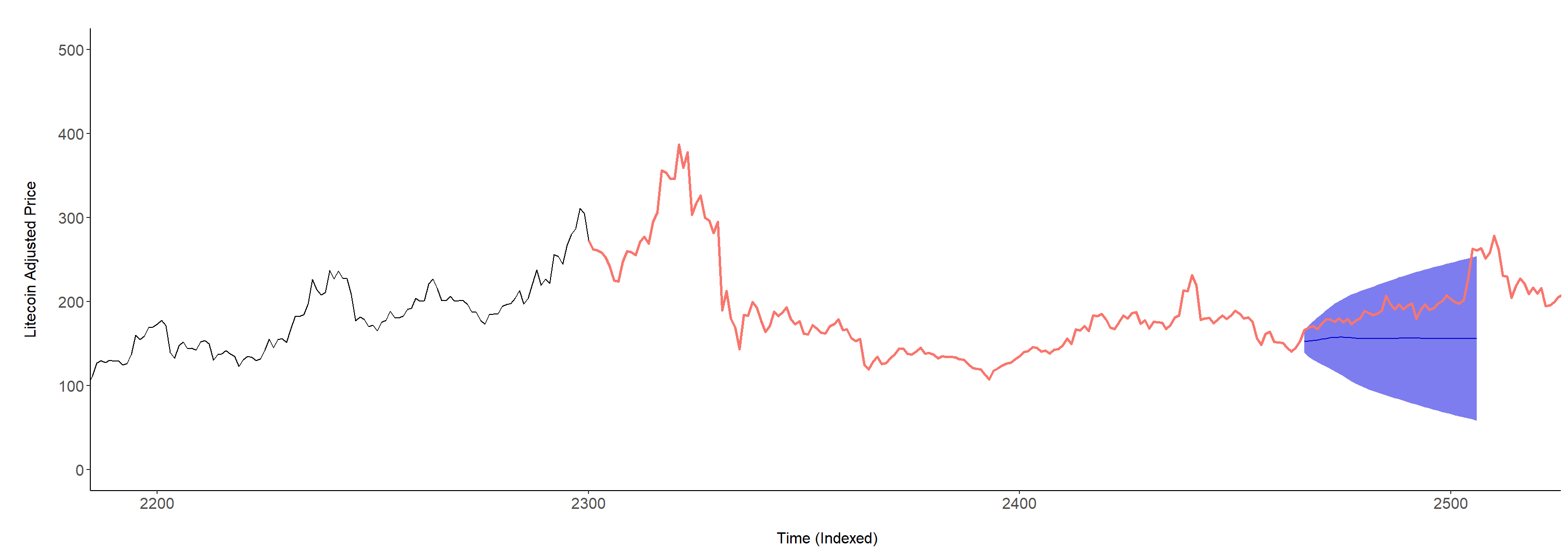
Note. Forecast prediction: Once Litecoin surpasses an adjusted closing price of $400, it will drop below $200 and continue to fluctuate normally (as expected), reaching a maximum value of $253.00 within the next 41 days.
Limitations
Predictions are made within a 95% confidence level based on a chi-squared distribution. Moreover, whereas the premise behind building GARCH(1,1) is to strengthen the case for volatility as a function of time, it is not used to make \(\ell\) step ahead forecasts in this paper. Subsequent explorations along these lines will only stand to strengthen pre-existing time series analyses of similar magnitudes. Furthermore, additional data visa vie larger sample size will be required to perform more robust, meaningful analyses (ARIMA included). Moreover, other variants of the GARCH model can be considered, like the GJR-GARCH model “developed in 1993 by Glosten, Jagannathan and Runkle” (Tsafack, 2021). One final note that is important to make is that the null hypothesis regarding the mean of the return warrants subsequent testing to establish whether it is possible to reject or fail to reject the premise that will remain at 14%.
Conclusion
Litecoin, one of the highly traded cryptocurrencies on the market possesses nonstationarity and high volatility, but substantial technological and financial potential. Its high skewness on all price (and volume) attributes aside, its periodical peaks can cycle every 675 and 1,350 days, which adds sentiment to a probable economic gain (thrust) in the near future. Differencing the time series is required, and from the tailing off of the ACF and PACF it is reasonable to use the ARIMA model on the cryptocurrency’s data to perform the forecast from the final model selection of ARIMA(3,1,3). In the next 41 days from November 30, 2021, the adjusted price should be fluctuating between $400 and $200 and then continue with its expected volatile movement.
This paper commences with the behaviors, characteristics, and historical movements of a highly rated cryptocurrency. It culminates with a forecast on its adjusted return, which is a direct byproduct of quantitative analysis. While past performance is not indicative of future results, a calculated effort is made so that investors can make informed decisions backed by facts and figures alone.
References
Bischoff, B. & Cockerham, R. (2019, March 31). Adjusted Closing Price vs. Closing Price. Zacks. Bohte, R., & Rossini, L. (2019). Comparing the forecasting of cryptocurrencies by Bayesian Time-varying volatility-
models. Journal of Risk and Financial Management, 12(3), 150. https://doi.org/10.3390/jrfm12030150
Ghalanos, A. (2020). rugarch: Univariate GARCH models.
Gidea, M., Goldsmith, D., Katz, Y., Roldan, & Shmalo, Y. (2020).-
Topological Recognition of Critical Transitions in Time Series of Cryptocurrencies.
Physica A: Statistical Mechanics and its Applications, 548, 1-22. https://doi.org/10.1016/j.physa.2019.123843
-
Journal of Financial Risk Management, 8, 15-28.
https://doi.org/10.4236/jfrm.2019.81002
-
2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), 286-291.
https://doi.org.sandiego.idm.oclc.org/10.1109/Confluence51648.2021.9377153
Shumway, R., & Stoffer, D. (2019). Time Series: A Data Analysis Approach Using R. Chapman and Hall/CRC.
Singh, A. (2018, August 30). Build High Performance Time Series Models using Auto ARIMA in Python and R.-
Analytics Vidhya. https://www.analyticsvidhya.com/blog/2018/08/auto-arima-time-series-modeling-python-r/
Tsay, R.S. (2013). An Introduction to Analysis of Financial Data with R. John Wiley & Sons, Inc.